Why It Is Time to Rethink How We Do Data Engineering?
The Process We Inherited
The way most enterprises run data engineering programs today was shaped 15 to 20 years ago. The tools have evolved. The platforms have evolved. But the process has not.
Discovery still means weeks of manual code reading and stakeholder interviews. Planning still means spreadsheets, T-shirt sizing, and estimation by analogy from a project that was "kind of similar." Architecture still means months of committee-driven design reviews before a single pipeline gets built. Engineering still means one data model designed by hand, one pipeline coded from scratch, one stored procedure converted at a time. Testing still means manually comparing outputs and hoping someone catches the edge cases.
This process made sense when there was no alternative. When the only way to understand a Teradata estate was to have a senior engineer read every stored procedure line by line. When the only way to estimate a migration was to extrapolate from past experience and round up for safety.
But the process also created problems that we learned to accept as normal:
Modernization programs that take 2 to 3x longer than planned. Estimates that miss by 40 to 60 percent, not because teams are bad at estimating, but because the estimation method itself is fundamentally flawed. Critical knowledge disappearing when a legacy SME retires, with no structured way to capture what they knew. Teams of 40+ engineers where 70 percent of the work is repetitive analysis and only 30 percent is actual engineering.
These are not failures of talent. They are failures of process and tooling. And the question worth asking now is: how much of this friction is inherent to the problem, and how much is a side effect of the tools we had available when the process was designed?
What Has Actually Changed
This is not a section about AI hype. Three specific things have changed in the last two to three years that are directly relevant to how data engineering work gets done.
Language models can now read and reason about code at scale
Not perfectly. Not autonomously. But well enough to parse thousands of SQL objects, extract structural metadata, classify complexity, map dependencies, and generate documentation at a speed and consistency that no manual process can match. The critical qualifier: this works when the AI is given proper context and structured domain knowledge, not just raw files dropped into a chat window.
Reasoning capabilities have improved enough to handle real enterprise SQL
Earlier models could manage simple SELECT conversions and basic syntax translation. Current reasoning models can work through multi-CTE queries, nested procedural logic, conditional branching, and moderately complex stored procedures. They can also generate new data models and pipeline code that follows platform-specific best practices when given the right architectural context. For the standard 60 to 70 percent of a typical enterprise SQL estate, the conversion accuracy is genuinely production-relevant. For new code generation, the output quality scales directly with the depth of domain knowledge and standards embedded in the prompt framework. For the remaining 30 to 40 percent of complex and edge-case-heavy objects, human engineering expertise is still essential.
The cost and speed of AI inference has dropped dramatically
Tasks that were theoretically possible but practically unaffordable two years ago are now viable at enterprise scale. Scanning 10,000 SQL scripts, classifying every object by complexity, generating documentation for an entire data estate: these are no longer experimental exercises. They are operational capabilities.
None of this means AI replaces data engineers. It means the manual, repetitive, high-volume parts of the data engineering lifecycle can now be accelerated in ways that were not possible before. The judgment, architecture, and domain expertise parts remain firmly human.
What It Means to Embrace AI Native Data Engineering
AI native data engineering is not about replacing your team with AI. It is about redesigning your data engineering workflows so that AI handles what it does well while your engineers focus on what requires human judgment.
Here is what this looks like at each stage of the lifecycle:
Discovery
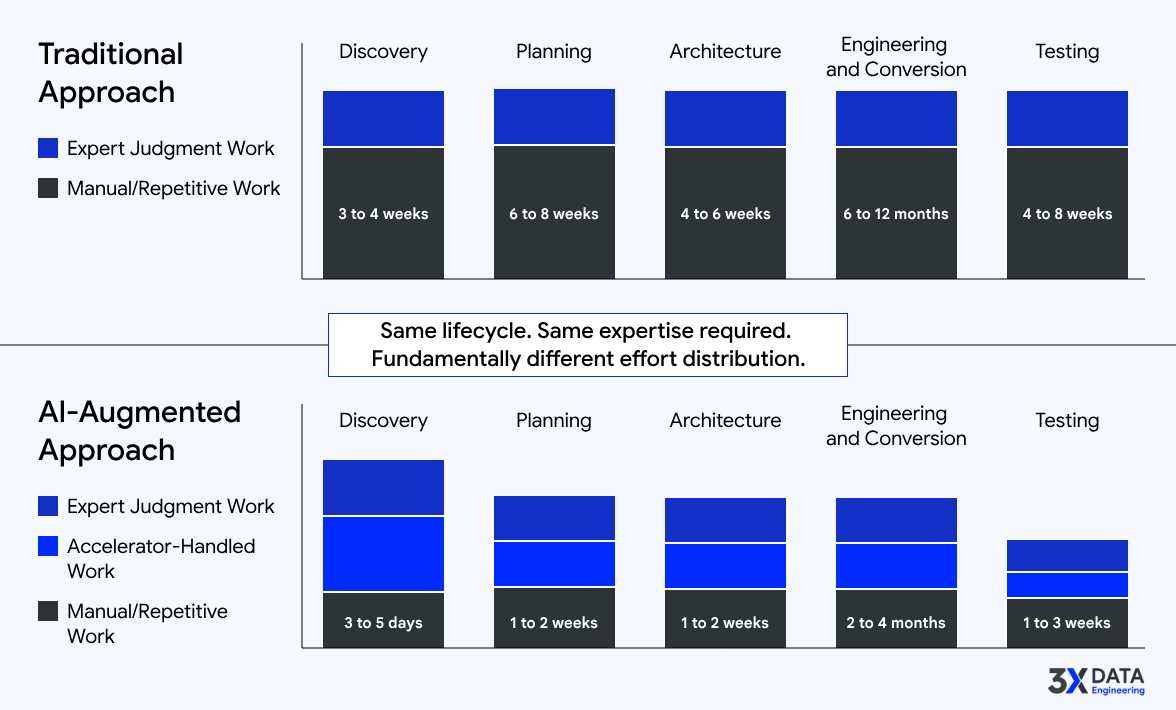
Instead of one engineer spending three weeks reading 500 stored procedures, an AI-powered engine scans the entire estate in hours. It extracts metadata, maps lineage, classifies objects by type and complexity, and produces structured documentation. Your senior engineer then spends two to three days reviewing and validating the output, focusing on the exceptions and ambiguities that the engine flagged. Three weeks becomes three days.
Planning
Instead of a spreadsheet estimate built from gut feel, an automated assessment engine scores every object by conversion complexity, maps the dependency graph, identifies high-risk clusters, and generates a phased roadmap with effort ranges backed by measured data. Your program manager reviews the plan, adjusts for organizational realities (team velocity, environment constraints, compliance overhead), and presents a defensible plan to leadership. Six weeks of manual analysis becomes one week.
Architecture
Instead of starting from a blank whiteboard, an AI-powered strategizer generates a first-principles architecture recommendation based on your data volumes, source systems, target platform capabilities, SLA requirements, and industry patterns. Your Distinguished Architect reviews, challenges, refines, and makes the final tradeoff decisions. The starting point is informed, not empty.
Engineering and Conversion
Data engineering projects are not all migrations. Some involve building entirely new data models, new pipeline code, and new platform implementations from scratch. Others involve converting thousands of legacy objects to a modern platform. Most involve both.
For new development, instead of an engineer spending days hand-crafting a dimensional model or writing boilerplate pipeline code from scratch, an AI-powered generation engine produces standards-compliant data models and production-ready pipeline implementations aligned to your target platform patterns. Your engineer reviews, refines, and extends the output, focusing their expertise on the business logic and design decisions rather than the scaffolding.
For conversion, instead of rewriting stored procedures one at a time, a bulk conversion engine processes hundreds of objects in parallel, applying platform-specific standards, enforcing naming conventions, and flagging objects that need manual intervention. Your engineers focus their time on the 30 to 40 percent that requires real engineering judgment, not the 60 to 70 percent that follows standard patterns.
In both cases, the accelerator handles the volume and the boilerplate. The engineer handles the thinking and the exceptions.
Testing
Instead of manually building comparison queries, AI generates test scaffolding, data reconciliation scripts, and validation frameworks. Your QA team defines the test strategy and interprets results. The setup work is automated. The judgment calls are human.
The pattern across every stage is the same: AI does the volume work. Humans do the thinking work. The lifecycle does not change. The effort distribution does.
Why We Started 3X Data Engineering
After 25+ years of building and delivering enterprise data programs at Fortune 10 scale, the pattern was impossible to ignore. The hardest parts of data engineering were not hard because the problems were unsolvable. They were hard because the right tooling did not exist.
We had world-class engineers spending weeks on work that should take days. We had architects whose rare expertise was consumed by repetitive analysis instead of being applied to the decisions that actually needed their judgment. We had programs that missed deadlines not because the team was slow, but because the manual process could not keep pace with the scale of the estate.
With our rare combination of deep enterprise data engineering experience and AI engineering capability, we wanted to explore every possibility for accelerating and optimizing the data engineering lifecycle. Not theoretically. Not as a research exercise. As production-grade tools that enterprise teams could use on real programs, against real SQL estates, with real deadlines.
That is what 3X Data Engineering is. An acceleration company built by practitioners who spent decades doing the work manually and who are now building the tools they wished they had.
We are not a consulting company that scales headcount. We are not a platform vendor that locks you into an ecosystem. We are a team that builds purpose-built accelerators, each one designed to solve a specific, high-impact problem in the data engineering lifecycle, and delivers them in a way that empowers your team to operate independently.
Where to Start
Every data program has a bottleneck. The right place to start with AI-augmented data engineering is wherever that bottleneck creates the most pain.
Start with the stage that hurts the most
For some teams, it is discovery: they do not know what they have, and every project begins with weeks of manual analysis before real work can start. For others, it is estimation: they cannot produce a plan that leadership trusts, and programs get funded on assumptions that fall apart in execution. For others, it is conversion volume: they have 5,000 objects to migrate and a 12-month deadline that is not negotiable. Identify your bottleneck. That is where acceleration delivers the fastest, most measurable return.
Measure your current baseline before you change anything
How many hours does your team spend on manual system analysis per 100 SQL objects? How long does it take to produce a modernization roadmap for a 1,000-object estate? What is your current conversion throughput per engineer per week? You cannot measure improvement without knowing where you started.
Run a proof of value, not a proof of concept
A proof of concept demonstrates that something is technically possible. A proof of value demonstrates that it delivers measurable improvement against your actual workload. Use your real SQL. Your real complexity distribution. Your real target platform. The results should be directly comparable to your current manual approach.
Do not try to automate everything at once
Start with one stage. Get the results. Build confidence internally. Then expand to the next stage. The organizations that succeed with AI-augmented data engineering are the ones that scaled incrementally based on evidence.
How It Helps: What Teams Actually Experience
This is not about features. It is about what changes when teams adopt this approach.
Program timelines compress
Discovery and assessment that used to take 6 to 8 weeks now takes 1 to 2 weeks. Teams start building sooner. Deadlines that seemed aggressive become achievable.
Estimates become defensible
When the CFO asks why the migration will cost $4M, the answer is grounded in measured object complexity, dependency analysis, and platform-specific conversion difficulty. Budget conversations shift from negotiations based on gut feel to discussions grounded in data.
Senior engineers work on senior problems
Instead of spending 70 percent of their time on repetitive analysis and routine conversions, architects and senior engineers focus on architecture decisions, edge case resolution, performance optimization, and quality strategy. The work matches the talent level.
Legacy knowledge gets captured before it disappears
AI-powered documentation captures system understanding at scale while the SMEs are still available to validate the output. When the legacy expert retires, the knowledge remains in the organization as structured, searchable intelligence.
Quality becomes more consistent
Accelerator-generated code follows enterprise standards by default. Naming conventions, error handling patterns, platform-specific best practices are embedded in the output, not dependent on whether the individual engineer remembered to apply them.
Teams scale without scaling headcount linearly
A team of 10 engineers with the right accelerators can cover the workload that previously required 25 to 30 engineers doing manual work. This is not about doing less. It is about focusing human effort on the work that actually requires human expertise.
3X Data Engineering's Core Offerings
Everything we do at 3X Data Engineering falls under three core services. Each one addresses a different dimension of how enterprise data teams need help, and together they cover the full spectrum from strategic guidance to hands-on acceleration.

1. Pre-Built Enterprise Accelerators
Our core portfolio of enterprise-grade engines and strategizers addresses the most common and highest-impact challenges across large-scale data programs. Every accelerator in this portfolio exists because of a specific problem we encountered repeatedly across enterprise engagements. Each one is purpose-built, not a wrapper around a generic AI tool.
2. Custom-Built Accelerators
Every enterprise has unique friction points that no pre-built tool can fully address. Proprietary ETL patterns, organization-specific coding standards, unusual platform combinations, domain-specific transformation logic. For these situations, 3X Data Engineering specializes in rapidly identifying the bottleneck, designing a targeted accelerator, and building it to production standards, often within days.
Custom accelerators are built to the same enterprise standards as our core portfolio and are tailored to a client's specific platforms, data domains, KPIs, and operational constraints. They integrate seamlessly into existing delivery workflows without disrupting what already works.
3. Strategic Advisory
Before accelerators, before automation, before any tooling conversation, there is a more fundamental question: what is the right approach for your specific situation?
Our strategic advisory practice brings Distinguished-grade expertise to the decisions that set the direction for everything downstream. Platform selection. Architecture design. Modernization sequencing. Program structure. Build-versus-buy tradeoffs. These are the decisions where getting it right saves millions and getting it wrong costs years.
This is not slideware consulting. It is hands-on, fact-based guidance from practitioners who have designed and delivered data programs at Fortune 10 scale. We work alongside your architects and leadership to make defensible decisions grounded in real system analysis, not vendor preferences or theoretical best practices.
How Our Pre-Built Accelerators Help Across the Lifecycle
Understanding Your Data Estate
The most common starting point for every data program is the same question: "What do we actually have?" Most organizations cannot answer it without months of manual effort.
Our Enterprise Metadata Intelligence Engine acts as an always-on metadata SME for large, complex data estates, enabling instant understanding of datasets, schemas, and lineage. The Distinguished Legacy Systems Intelligence Engine produces authoritative documentation and deep system understanding for undocumented or poorly understood legacy platforms. The Intelligent Reverse Engineering Engine performs source-connected, object-level system deconstruction that reveals structures, logic, dependencies, and data flows with precision.
Together, these engines turn opaque data estates into well-understood, navigable assets. For teams facing modernization deadlines with thousands of undocumented objects, this is often where acceleration delivers the most immediate impact.
Planning with Facts
The Fact-Based Modernization Roadmap and Effort Estimator produces SI-grade, defensible modernization plans and effort estimates grounded in real system analysis. It scans your estate, classifies every object by conversion complexity, maps the dependency graph, and generates a phased roadmap with effort ranges backed by measured data.
It exists because the industry's approach to data engineering estimation is fundamentally broken. Programs should not be funded on assumptions and T-shirt sizing when they can be funded on measured complexity. When your VP of Data Engineering takes this roadmap to the CFO, the numbers hold up because they are derived from actual system analysis.
Designing with Rigor
The Distinguished Greenfield Architecture Strategizer provides first-principles platform design for new data programs, optimized for scalability, cost, and long-term evolution. The Distinguished Brownfield Modernization Strategizer delivers phased, low-risk modernization strategies for complex legacy environments with minimal business disruption. The Distinguished Architect Grade Data Modeling Generator produces standards-compliant, enterprise-ready conceptual, logical, and physical data models.
These exist because architecture decisions set the trajectory for everything downstream, and most teams do not have access to Distinguished-grade architectural expertise on demand. Whether you are building a new lakehouse from scratch or modernizing a legacy warehouse with 15 years of accumulated complexity, the architecture accelerators give your team an informed starting point backed by enterprise best practices.
Engineering and Converting at Scale
Data engineering programs are rarely just migrations or just greenfield builds. Most involve both: new data models and pipelines that need to be designed and built from scratch, alongside thousands of legacy objects that need to be converted to a modern platform.
The Distinguished Architect Grade Data Modeling Generator produces standards-compliant conceptual, logical, and physical data models for new development, ensuring that greenfield work starts with enterprise-grade foundations rather than ad hoc designs that accumulate technical debt. The Distinguished Engineer Grade Data Pipeline Code Generation Engine produces production-ready pipeline implementations with performance, scalability, and governance built in, whether the pipeline is brand new or a modernized version of legacy logic.
For conversion workloads, the Enterprise Bulk Code Conversion Factory handles large-scale, automated conversion of SQL and ETL estates to modern platforms with consistency and quality controls. It processes hundreds of objects in parallel, applying platform-specific standards and flagging objects that require manual intervention.
Together, these accelerators cover the full spectrum of engineering work. A team of 10 engineers using them can deliver what previously required 25 to 30 engineers working manually, with more consistent quality because enterprise standards are enforced by the accelerator, not dependent on individual discipline.
Testing with Confidence
The Enterprise Synthetic Data Factory enables safe, production-grade synthetic data generation for testing, validation, and AI training without exposing sensitive data. It exists because testing with production data creates compliance risk in regulated industries, and building realistic test datasets manually is painfully slow.
For financial services, insurance, and healthcare organizations, this accelerator solves a problem that blocks progress on nearly every modernization program: how to validate thoroughly without violating data privacy requirements.
How We Deploy
We meet you where you are, technically and operationally.
Accelerators can be deployed directly within your existing infrastructure (client-hosted), in secure cloud environments for scalability and managed execution (cloud-hosted), or fully on-premises on DGX Spark or equivalent systems for organizations that require 100 percent data privacy and compliance (sovereign on-prem deployment).
With our source ownership model, clients receive full source code along with documentation and training to operate, maintain, and enhance the accelerators independently. This is deliberate. Our goal is to empower your team, not create dependency. The best outcome is a client team that can eventually run and evolve the accelerators on their own.
The Bottom Line
The data engineering lifecycle is not going to change itself. The same manual processes that have been the norm for 15 years will stay the norm unless teams actively choose to work differently.
The tools now exist to accelerate the most time-consuming, repetitive, and error-prone parts of the lifecycle without sacrificing engineering quality. The question is not whether AI-augmented data engineering works. It does. The results are measurable. The question is whether your team will adopt it early and gain the advantage, or continue with the manual approach while the industry moves forward.
Start with your biggest bottleneck. Measure the current cost. Run a focused proof of value. Let the results guide the next step.
3X Data Engineering was built by practitioners who have spent decades doing this work and who understand both the potential and the limits of AI in this domain. We are here to help data engineering teams become measurably faster, one stage of the lifecycle at a time, in a practical and realistic way.
If your team is dealing with a large legacy estate, a looming migration deadline, unreliable estimates, or the pressure to make your data foundation AI-ready, we would welcome a technical conversation about whether acceleration can help. Not a sales call. A conversation between engineers about a shared problem.
That is what we do at 3X Data Engineering. We build the tools that make enterprise data engineering teams measurably better, and we want every data team in the industry to start thinking this way, whether they work with us or not.
Hariharan Arulmozhi - Founder & CEO, 3X Data Engineering
3X Data Engineering is an enterprise data engineering acceleration company that helps organizations understand, modernize, and scale complex data estates using Distinguished-grade AI accelerators. Learn more at 3xdataengineering.com


