AI Augmented Data Engineering: The Art of Possible
Why "Augmented" Is the Right Word
The industry keeps reaching for "AI native" and "autonomous" when what actually works today is "augmented."
The distinction matters. Autonomous implies AI runs the show. Augmented means AI handles the volume, the repetition, and the structural analysis while humans handle the judgment, the context, and the decisions that compound.
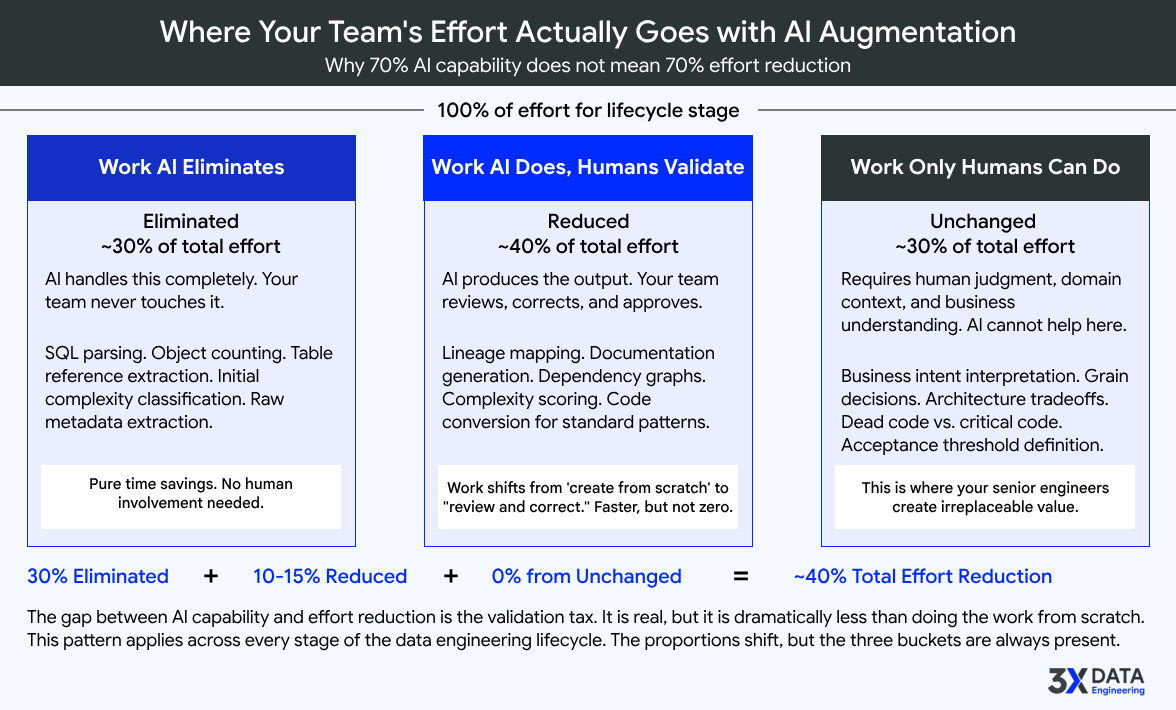
This is not a consolation prize. AI-augmented data engineering, done well, delivers 30 to 50 percent effort reductions across most lifecycle stages. On a multi-million-dollar program, that translates to months of compressed timeline and significant budget savings.
The key qualifier: "done well" means AI applied within a structured framework with embedded domain knowledge. Not generic LLM prompts against raw SQL files. Not ChatGPT with a pasted stored procedure. Purpose-built acceleration with enterprise context baked in.
This blog walks through each stage of the data engineering lifecycle and shows what AI augmentation actually looks like today: what AI handles, what humans own, the realistic capability level, and the measurable effort reduction. No hype. Just the art of the possible, grounded in what works.
Two Numbers That Tell Different Stories
For every stage of the data engineering lifecycle, two numbers matter. Most people only look at one.
AI Technical Capability
measures how good AI is at performing the tasks within a stage. Can it parse SQL? Can it classify complexity? Can it generate a data model? This is the number vendors showcase in demos.
Actual Effort Reduction
measures how much human effort actually decreases when AI is applied with proper domain context. This is the number that shows up in your program timeline and budget.
The second number is always lower than the first. The gap between them tells you something critical.
The gap exists because capability is not the same as applicability. AI might be 80 percent capable at parsing and classifying SQL objects. But the effort reduction for the overall assessment stage is 40 to 60 percent because the remaining work (organizational context, risk judgment, sequencing decisions) is not a parsing problem. It is a human judgment problem.
Understanding this gap is what separates teams that get real value from AI augmentation from teams that get disappointed.
Stages where the gap is narrow are where you get the highest ROI. Stages where the gap is wide are where human expertise dominates regardless of how advanced the AI becomes. Both are important to understand before you invest.
Stage by Stage: What AI Augmentation Actually Looks Like
Discovery and Understanding
AI Capability: 70% | Effort Reduction: 30 to 50%
Every data program starts with understanding what exists. In most enterprises, this means weeks of manual code reading, stakeholder interviews, and documentation that turns out to be outdated or wrong.
AI changes the economics of this stage. LLMs combined with systematic metadata extraction frameworks can parse thousands of SQL objects, extract table and column references, map basic data lineage, and generate structured documentation from code. When fed the right context from database catalogs, schema definitions, and execution logs, the output quality is genuinely useful.
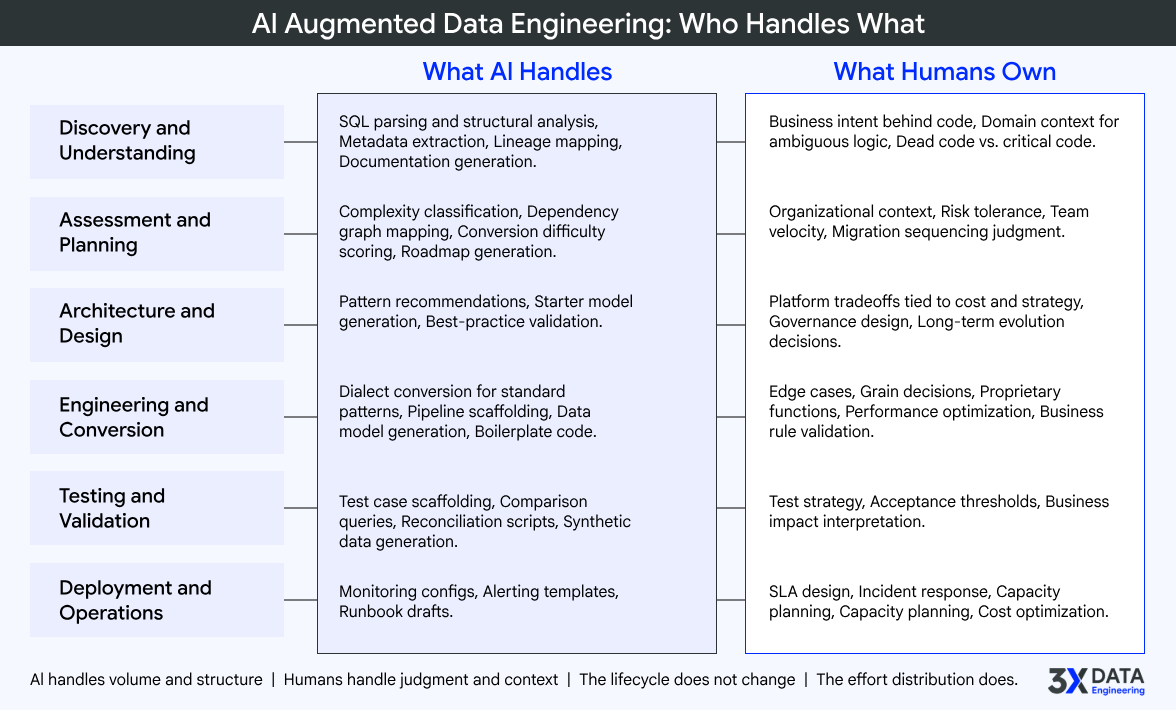
What humans own: business intent behind the code. A CASE statement with 47 conditions is parseable. Knowing that those conditions represent a regulatory premium adjustment algorithm that must be preserved exactly during migration is not. Domain context, ambiguity resolution, and the judgment call between dead code and critical code remain human territory.
At 3X Data Engineering, our Enterprise Metadata Intelligence Engine and Distinguished Legacy Systems Intelligence Engine are built specifically for this stage. They combine structural parsing with deep data engineering domain knowledge to produce documentation and system intelligence that enterprise teams can act on immediately, not generic summaries that need additional interpretation.
Verdict: AI does the structural heavy lifting. Humans interpret meaning
Assessment and Planning
AI Capability: 80% | Effort Reduction: 40 to 60%
This is where most enterprise data programs lose months before real work begins. Spreadsheet estimates, T-shirt sizing, analogies from unrelated past projects. The planning process itself becomes a bottleneck.
AI-powered assessment replaces this with measured, fact-based analysis. Automated complexity scoring can classify thousands of objects by conversion difficulty in hours, not weeks. Dependency graph mapping reveals the real structure of your estate. Platform-specific conversion difficulty scoring gives you a defensible basis for effort ranges. Phased roadmap generation produces SI-grade plans grounded in actual system data.
What humans own: organizational context that no system scan captures. Team velocity, stakeholder alignment overhead, change management friction, compliance review cycles, environment provisioning timelines. AI tells you the engineering effort. Humans add the organizational reality.
The Fact-Based Modernization Roadmap and Effort Estimator from 3X Data Engineering exists specifically because the industry's approach to data engineering estimation is broken. Programs should not be funded on assumptions when they can be funded on measured complexity.
Verdict: Highest ROI stage. Replaces weeks of manual analysis with days. Start here if your estimates keep missing
Architecture and Design
AI Capability: 30% | Effort Reduction: 15 to 25%
This is the most judgment-intensive stage in the lifecycle. Architecture decisions compound for years. Lakehouse versus warehouse, medallion versus data vault, batch versus streaming versus hybrid, single-platform versus multi-platform. Every choice constrains what comes after.
AI can help with pattern recommendations based on stated requirements, starter data model generation, best-practice validation against known patterns, and platform feature comparison. These are useful starting points that save the architect from a blank whiteboard.
What humans own: everything that involves tradeoffs tied to cost, organizational strategy, team capability, regulatory constraints, and long-term evolution. The decision about whether to use Snowflake dynamic tables or dbt incremental models depends on cost sensitivity, team SQL proficiency, latency requirements, existing tooling investments, and platform strategy. No LLM has access to these organizational factors.
The Distinguished Greenfield Architecture Strategizer and Distinguished Brownfield Modernization Strategizer from 3X Data Engineering give architects an informed starting point grounded in enterprise best practices. They do not replace architectural thinking. They accelerate it by providing a structured, fact-based foundation to build on.
Verdict: AI as copilot. Humans make the decisions that compound
Engineering and Conversion
AI Capability: 65% | Effort Reduction: 30 to 50%
This stage covers both converting legacy objects and building new ones. Most enterprise programs involve both: thousands of SQL scripts to migrate AND new data models, pipelines, and platform implementations to build from scratch.
For conversion, AI handles SQL dialect translation for standard patterns, and 60 to 70 percent of a typical enterprise estate falls into this "standard" category. For new development, AI generates data models from requirements descriptions, produces pipeline scaffolding for target platforms, and creates boilerplate code for common patterns like SCD implementations, incremental loads, and data quality checks.
What humans own: the long tail. Edge case resolution for both converted and newly built code. Grain decisions for new dimensional models that depend on how the business actually uses the data. Proprietary function handling that exists in no training data. Performance optimization for actual data volumes. Business rule validation that requires understanding what the data means, not just how it flows.
3X Data Engineering's Distinguished Engineer Grade Data Pipeline Code Generation Engine and Enterprise Bulk Code Conversion Factory address both sides of this workload. They embed platform-specific standards and enterprise coding conventions into every output, whether the code is newly generated or converted from a legacy source.
Verdict: AI handles volume and boilerplate. Humans handle judgment and edge cases.
Testing and Validation
AI Capability: 40% | Effort Reduction: 20 to 35%
Testing data systems is different from testing software applications. The question is not "does it compile" but "does it produce the right business outcomes." And "right" is context-dependent.
AI handles the time-consuming setup work: test case scaffolding, data comparison query generation, reconciliation script creation, and synthetic test data generation. These tasks slow testing cycles significantly when done manually.
What humans own: test strategy and coverage decisions. Acceptance threshold definition. A 0.01 percent variance in financial reconciliation is a critical defect. A 5 percent variance in marketing attribution might be perfectly acceptable. Knowing which standard applies to which pipeline is a domain judgment call.
The Enterprise Synthetic Data Factory from 3X Data Engineering addresses one of the most common testing blockers in regulated industries: generating realistic, production-grade test data without exposing sensitive information.
Verdict: AI builds the scaffolding. Humans define what correct means
Deployment and Operations
AI Capability: 20% | Effort Reduction: 10 to 15%
This is the most human-driven stage. Operating data pipelines at enterprise scale is fundamentally about organizational knowledge, not code generation.
AI handles monitoring configuration templates, alerting threshold suggestions, and runbook drafts. Useful starting points, but a small fraction of the overall operational workload.
What humans own: SLA contract design, incident response and escalation procedures, capacity planning tied to business cycles, cost optimization decisions that balance performance against budget, and the organizational coordination that keeps production systems running reliably.
Verdict: Mostly human. AI assists at the margins
The Pattern That Matters
Three observations emerge from looking at all six stages together.
The highest ROI is not where AI capability is highest
Assessment and Planning (80% capability, 40 to 60% effort reduction) delivers more measurable value than Engineering and Conversion (65% capability, 30 to 50% effort reduction). Why? Because time saved in planning has a multiplier effect on everything downstream. A better estimate prevents budget overruns. A better roadmap prevents wasted sprints. Upstream stages have disproportionate leverage.
The gap between capability and effort reduction is your human expertise requirement
Where the gap is narrow (Assessment), AI is doing most of the useful work and lighter senior oversight is sufficient. Where the gap is wide (Architecture, Deployment), human judgment dominates regardless of AI advancement. Staffing decisions should follow this pattern. Put your most experienced architects on the wide-gap stages. Let AI-augmented workflows handle the narrow-gap stages with review-level oversight.
All percentages assume a structured framework, not generic LLM usage
A team dropping SQL files into ChatGPT will not see 30 to 50 percent effort reduction. A team using purpose-built accelerators with embedded domain knowledge, platform-specific patterns, and enterprise standards will. The framework is the multiplier. The LLM is just the engine inside it. This is the core design principle behind every accelerator 3X Data Engineering builds.
Where to Start

Look at your current program and ask: which stage consumes the most time, costs the most, or creates the most risk?
If the answer is discovery:
you have an opacity problem. Your team does not know what they have. Start with metadata intelligence and reverse engineering accelerators. Measure your current baseline of manual analysis hours per 100 objects before you begin.
If the answer is planning:
you have a credibility problem. Your estimates do not hold up. Start with fact-based assessment. The ROI here is not just time saved but stakeholder confidence gained. When the CFO trusts your numbers, programs get funded faster.
If the answer is engineering and conversion volume:
you have a throughput problem. Start with a proof of value on a representative 50 to 100 object subset. Measure conversion accuracy, generation quality, and human review time against your fully manual approach.
If the answer is architecture:
you have a decision-speed problem. Your team spends months in design committees before a single pipeline goes live. Start with architecture strategy accelerators that provide an informed starting point rather than a blank whiteboard.
If the answer is testing:
you have a validation bottleneck. Start with test scaffolding automation and synthetic data generation. Measure how much of your testing cycle is setup versus actual validation.
In every case: start with one stage, measure the results, then expand based on evidence. The organizations that scale AI augmentation successfully are the ones that build confidence incrementally.
The Bottom Line
AI augmented data engineering is not a future state. It is available today, delivering measurable results across every stage of the lifecycle.
The effort reductions are real: 30 to 50 percent in discovery, 40 to 60 percent in assessment, 15 to 25 percent in architecture, 30 to 50 percent in engineering and conversion, 20 to 35 percent in testing. These are outcomes from applying structured frameworks with embedded domain knowledge to real enterprise workloads, not theoretical projections.
The art of the possible is not about replacing your data engineering team. It is about removing the manual, repetitive, high-volume work from their plate and letting them focus on the judgment, architecture, and domain expertise that no AI can replicate. That is where your senior engineers create the most value. That is where your program succeeds or fails.
3X Data Engineering builds the accelerators that make this real. Purpose-built, domain-rich, enterprise-grade. Every accelerator in our portfolio exists because of a specific problem we encountered repeatedly across Fortune 10-scale data programs. We embed Distinguished-grade data engineering expertise directly into the tooling so your team gets the benefit of that experience from day one.
If you want to see what these numbers look like against your actual data estate, we run proof-of-value engagements that deliver measurable results within weeks. Not a sales demo. A real test against your real workload.
The art of the possible is already here. The question is whether your team will use it.
3X Data Engineering is an enterprise data engineering acceleration company that helps organizations understand, modernize, and scale complex data estates using Distinguished-grade AI accelerators. Learn more at 3xdataengineering.com


